
Cluster-based Masking as an Efficient Pretraining method
We introduce a simple masking strategy that randomly drops out clusters. Firstly, we break the image into patches. Next, we compute the pairwise cosine similarity between each pair of normalized patches. We randomly select a small subset (less than 5%) of these patches to serve as cluster centers, which we refer to as anchor patches. For each anchor patch, we define a cluster that includes all patches within a specified distance 𝑟.

Experiment Results
Cluster Visualization:
We visualize the clusters of patches obtained from our masking strategy. Each grid belongs to a cluster, with patches from the same cluster grouped together. Hover over the patches to see the clusters they belong to.
Zero-shot Vision-Language Retrieval:
We evaluate image-text retrievals MS-COCO, Flickr8k, and Flickr30k datasets. Our model outperforms the baselines in most benchmarks.
We evaluate our model on several widely recognized classification benchmarks and outperforms all the baselines on both zero-shot classification and linear probing.
Language Composition:
We use Sugar-Crepe to test our model's ability to understand language compositions, our model yields comparable results in Relation tests and demonstrates a significant enhancement in Object and Attribution tests.
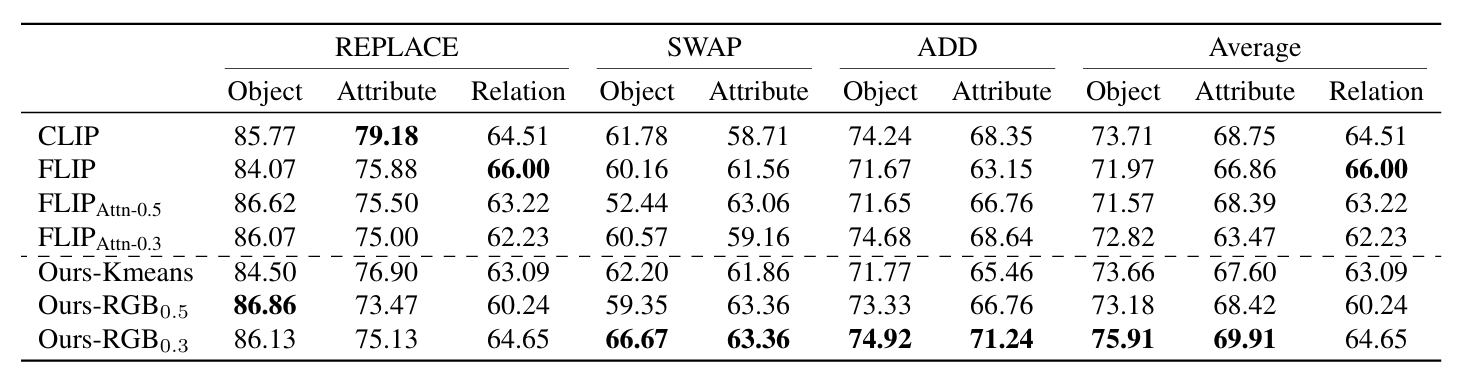
This table presents the performance of models on the Sugar-Crepe evaluation, which involves replacing, swapping, or adding atomic concepts such as objects, attributes, and relations in a sentence to create mismatched captions.
BibTeX
@article{clustermasking2024,
title={Efficient Vision-Language Pre-training by Cluster Masking},
author={Wei, Zihao and Pan, Zixuan and Owens, Andrew},
year={2024},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}
}